
"Hit my Claude limit" is the new flex
...and what I do now to keep my AI working. Everything you need to know and a framework.

AI tokens got roughly 1,000x cheaper in three years. My AI bill went from $0 to $200 — and $200 wasn’t enough.
Last week I was upgrading our startup’s UI while one agent scanned industry trends in the background and Claude chewed through transcripts from a user interview and an adviser meeting we’d just had. Normal Tuesday.
Then the screen told me I’d hit my limit on max Claude’s Max plan.

So… I read Dostoevsky. Spent additional time with my 1-year-old. Baked a quiche. It turned out a very good break, but…
I thought I was doing something wrong. Then my friends started showing off. “Hit my limit by 2pm today.” It’s a flex now.
Uber burned through its annual AI budget a few months into 2026. Engineering max plans run $100-200 per person — one CTO ran $600 bills. My number wasn’t high. It was the floor.
You don’t plan to overspend on AI. Or on Sicily vacation. The bill comes anyway.
Where 99.93% of your tokens go
So, my first instinct was to blame myself — maybe my mempalace plugin config was bloated, maybe my system instructions were too long. I trimmed both. Still hit the limit.
I asked Claude to audit its own token usage:

It re-read and re-wrote again and again.
A developer who audited 30 days of Claude Code put a number on it: 1,310 re-reads per 1 productive token. 99.93% of what I was paying for was the machine reading what it already knew.

I kept pulling the thread. One wall became a stack.
The routing tilts expensive: Claude Code sends 93.8% of tokens through Opus, the priciest model in the lineup.
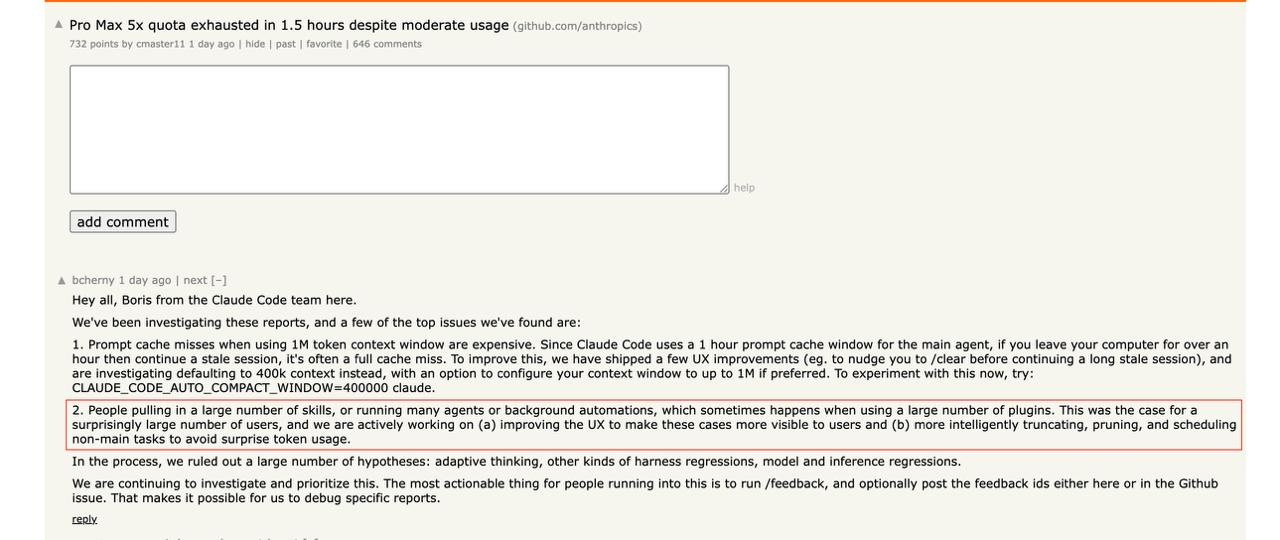
A friend sent me a Hacker News screenshot. Boris Cherny, Claude Code creator, was explaining why bills spike: million-token contexts get expensive fast, and background agents trigger surprise charges for “a surprisingly large number of users.” The thread had 750+ points and 650+ comments.
Agents are voracious — agentic workflows use 5-30x more tokens than a chatbot, multi-agent setups about 15x more than a single chat. They don’t know which files they need, so they read everything — 60-80% of tokens wasted just locating code. Every MCP plugin ships its tool schemas with every call; one team found 72% of their context window eaten by tool definitions before the agent saw a single message. I was running 30 agents with mempalace, GitHub, and Slack plugins. I ran around 30 agents daily. The math was not in my favor.
Thinking tokens bill at output rates, 5x input. Self-attention scales quadratically: double the context, quadruple the compute. Each layer multiplies through the others faster than I could trim.
Economists call this Jevons Paradox. a16z calls it “LLMflation”. Cheaper units don’t reduce consumption. They unlock it.
At the same time Anthropic pays even more.
One user calculated their virtual cost at $1,274 a month — on a $200 plan. Anthropic eats the difference today; that subsidy won’t last.
DeSight Studio’s analysis puts the platform-side number at roughly $5,000 of inference compute burned per $200 Max subscriber. That’s not a small gap a price hike closes; it’s 25x. Every heavy user is being underwritten by venture capital and the implicit promise that someone, eventually, pays full price.
Designing around the bill
When my token bill kept climbing, I stopped trying to push it down and started designing around it.
So I tried the obvious fixes first.
Killed half my skills and plugins — the ones I’d installed once and forgotten. Cleaner config, it helped a bit. The overhead wasn’t in the tools I’d stopped using; it was in the ones I used every day.
Compacted earlier, cleared more often. Middle of a pitch deck final, I ran /compact too soon — the thread I’d been chasing got summarized into a sentence, and the investigation was gone. I spent the next hour rebuilding what I’d just discarded.
Routed the cheap work to Haiku. Extracting action items from a user research transcript seemed like pattern-matching. It wasn’t. Haiku returned generic bullets that missed the three decisions the customer had actually announced. I reran on Opus, ate two passes instead of one, plus the time I’d lost trusting the first output.
Switched to Cursor one day when Claude locked me out again — same folders, same files, two hours. It was fun, I realized that I’m truly model agnostic as well as my work, but I still prefer Claude.
The token-by-token war was unwinnable. Every fix bought back a few percent that the next agent run spent twice over. I needed a discipline.
Every cheap technology creates an expensive discipline
You read this far — here’s a small thank-you. If you want to keep reading (this post + every past post), your first month is $5.20, that’s 60% off. Feel free to cancel in the first 30 days and you pay nothing more.
The $5 link is open until June 1st. After that, it goes back to full price.