
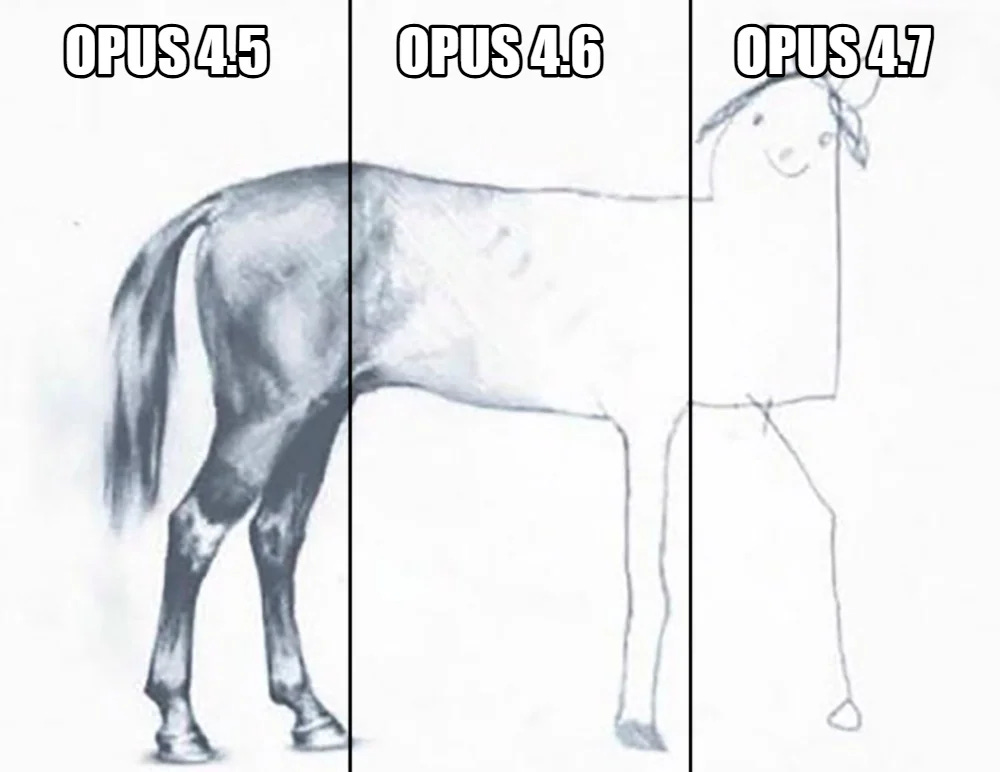
I lost an afternoon to Opus 4.7 last week
Claude Opus 4.7 feels worse because it stopped covering for your implicit prompts. 3 practices to fix it. And why AGI is not coming anytime soon.

I lost an afternoon to Opus 4.7 last week — installed it mid-project, watched it take longer than 4.6 and then fail. Half my feed was already complaining.
Burned my usage limit faster than expected — 4.7 costs more per token than 4.6. Switched to Gemini to get things done.
Hey! I’m Alena — ex-AI-startup CEO ($2M raised), ex-PM at Yandex and Acronis. 11k L…
