
I rebuilt AI agent 10 times. Spoiler: it was never about cutting-edge model.
How harness engineering turned my failing system around.

The next AI model won’t fix your agents. I know because I used the same Claude for 10 versions of the same system. What actually changed my results was everything around the model — the instructions it reads, the tools it can use, the checks that catch its mistakes.
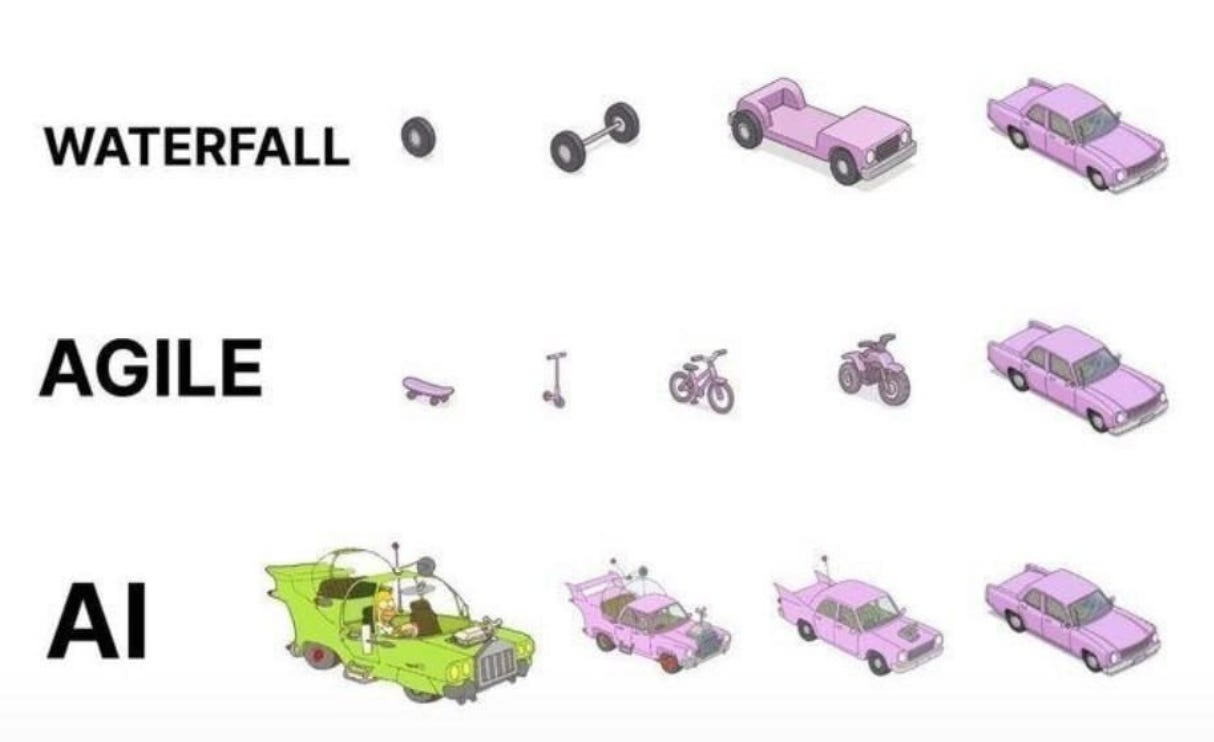
Everything you build around the model — the instructions, the tools, the error handling, the pipeline — developers call this the harness. Mitchell Hashimoto, who built Terraform, gave it a simple rule: every time your agent makes a mistake, engineer a fix so it never makes that mistake again.
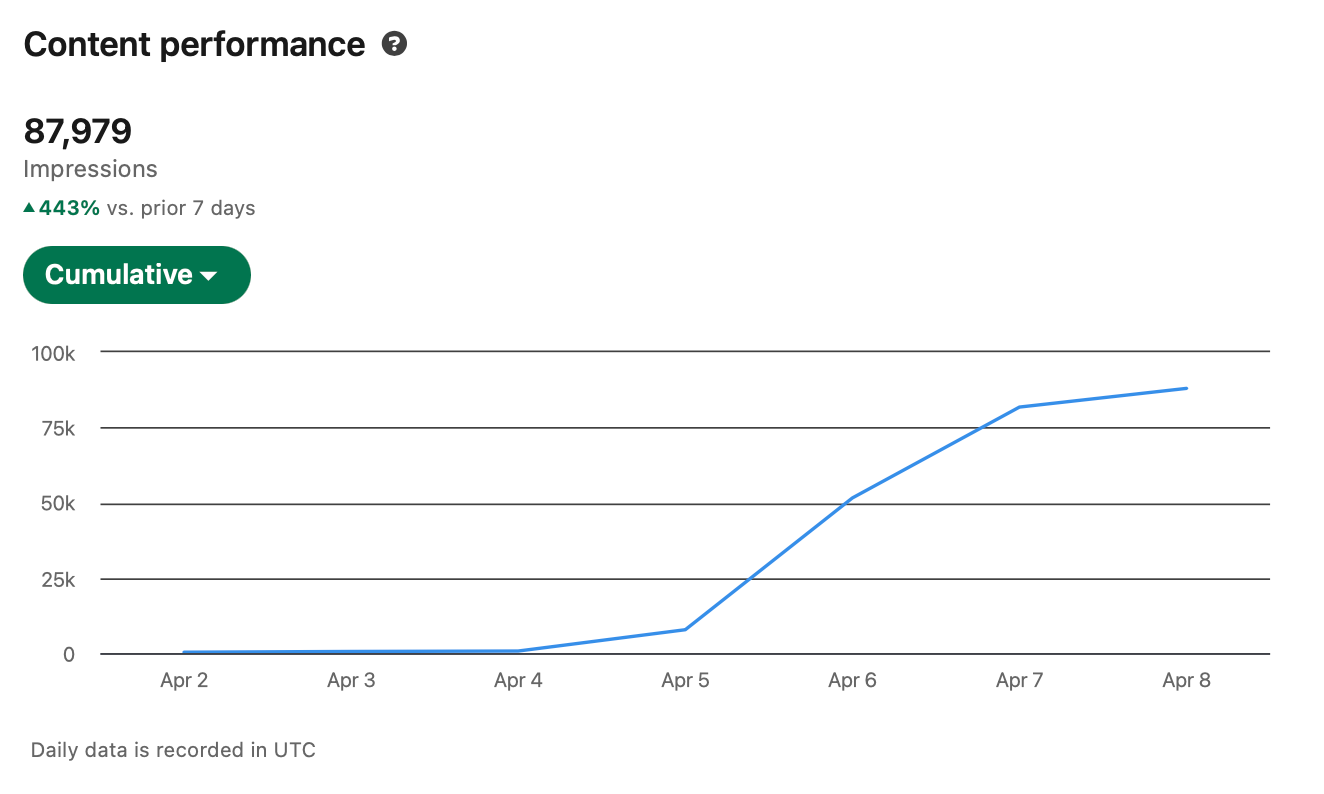
All of this research comes from the engineering world. But I applied the same principles to my trendwatching agent — and it brought me 85K impressions on LinkedIn in 3 days by finding the hottest.
The Context
(skip if you want to apply harness asap)
When there’s no marketing budget, you ARE the marketing. For me that meant LinkedIn — and LinkedIn meant knowing what’s trending before everyone else. That was 3 hours of my morning, every morning. I tried to automate it. Ten times.
The first six versions were a slow education in what doesn’t work. I started by dumping everything into one Claude conversation — worked until the context window filled up and the model forgot what it had already read. Then I vibe-coded Python scripts with a scoring system, but spent more time calibrating scores than the system was saving me. Then I added 9+ sources across languages and the volume drowned the model in noise — hallucinations, missed items, everything still crammed into one agent’s context.
Version 7 broke me. I tried giving every single content piece its own dedicated agent. Three hours of compute that never resolved. Then the opposite — blind parallel pipelines with no monitoring. 45 minutes, garbage output. Both extremes failed for the same reason: I was engineering around the wrong problem.
Version 9-10 was a full rebuild. Monitored background agents instead of blind subprocesses. Evals at every phase with fallback instructions for when things break. An orchestrator that takes over when subagents fail. The specifics are the seven principles below.
Runtime went from 45 minutes to 15, reliability went from “maybe works” to something I’d actually stake my LinkedIn on — and it’s still the same Claude.
Here are 6 harness principles I applied:
1. Give the AI less, not more
Version 7 ran for 3 hours and never finished because the agent was doing everything — fetching data, routing APIs, handling files, analyzing, scoring, formatting output. I kept throwing more at Claude because that’s what felt natural — more tools, more responsibility, more context — and three hours later I had nothing.
I split the work — Python fetches, Claude analyzes. The scoring agent sees only the scoring rubric and the raw items, no pipeline logic, no historical context, and scores improved immediately.

Vercel learned this too. Their text-to-SQL agent had 17 tools. They deleted 15, gave the model bash and file access. 100% accuracy. 3.5x faster. 37% fewer tokens. The model wasn’t confused by the task — it was confused by the choices.
Birgitta Bockeler from Thoughtworks: “Increasing trust and reliability requires constraining the solution space rather than expanding it.”
2. Evals and Plan B
You read this far — here’s a small thank-you. If you want to keep reading (this post + every past post), your first month is $5.20, that’s 60% off. Feel free to cancel in the first 30 days and you pay nothing more.
The $5 link is open until June 1st. After that, it goes back to full price.
